从主观的角度来看,已有数十篇文章比较了Python与R。大数据分析Python和R语言的优缺点旨在更客观地研究语言。我们将在Python和R中并排分析数据集,并显示两种语言需要哪些代码才能获得相同的结果。这将使我们无需猜测即可了解每种语言的优点和缺点。在AAA教育,我们教授两种语言,并且认为这两种语言在数据科学工具包中都占有一席之地。
我们将分析NBA球员及其在2013-2014赛季的表现数据。对于分析的每个步骤,我们将显示Python和R代码,以及对不同方法的一些解释和讨论。事不宜迟,让我们开始这场Python vs R对决!
导入CSV
[R

Python

上面的代码会将CSV文件nba_2013.csv(包含2013-2014赛季NBA球员的数据)加载到nba两种语言的变量中。唯一的实际区别是在Python中,我们需要导入pandas库才能访问数据框。在R中,虽然我们可以使用基本R函数导入数据read.csv(),但使用readr库函数read_csv()的优点是速度更快,并且数据类型的解释一致。数据框在R和Python中均可用,并且是二维数组(矩阵),其中每一列可以具有不同的数据类型。在此步骤结束时,两种语言均已将CSV文件加载到数据框中。
查找行数
[R

Python

这将打印出播放器的数量和每个播放器中的列数。我们有481行或播放器,以及31包含播放器数据的列。
查看数据的第一行
[R

Python

这几乎是相同的。两者都打印出数据的第一行,并且语法非常相似。Python在这里更面向对象,并且head是数据框对象的方法,而R具有单独的head功能。当我们开始使用这些语言进行分析时,这是一个常见的主题。Python更面向对象,R更实用。
查找每个统计的平均值
让我们找到每个统计的平均值。如我们所见,这些列的名称如fg(制定了目标)和ast(辅助)。这些是球员的赛季统计数据。(如果您想对所有统计信息进行更全面的说明,请查看此处。)
[R

Python

此处,Python和R的方法存在一些主要差异。在这两种方法中,我们都在数据框列上应用了一个函数。在Python中,默认情况下,数据框上的mean方法将查找每列的平均值。
在R中,我们可以使用两个常用软件包中的函数来选择要平均的列,然后将mean函数应用于它们。%>%称为“管道” 的操作员将一项功能的输出作为下一项功能的输入。取字符串值的平均值只会导致NA-不可用。我们可以使用来仅取数字列的平均值select_if。
但是,我们NA在取平均值时确实需要忽略值(要求我们传递na.rm=TRUE给mean函数)。如果不这样做,则最终NA得到像列的均值x3p.。此列是三点百分比。一些球员没有三分球命中率,所以他们的百分比失了。如果我们尝试使用meanR中的函数,则会得到NA响应,除非我们指定na.rm=TRUE,否则NA在取平均值时会忽略值。.mean()默认情况下,Python中的方法已经忽略了这些值。
进行成对散点图
探索数据集的一种常用方法是查看不同的列如何相互关联。我们会比较ast,fg和trb列。
[R

Python

最后,我们得到了非常相似的图,但这表明R数据科学生态系统如何具有许多较小的程序包(GGally是ggplot2的帮助程序包,即ggplot2,是最常用的R绘图程序包),并且通常还有更多可视化程序包。在Python中,matplotlib是主要的绘图程序包,而seaborn是matplotlib上广泛使用的层。使用Python进行可视化,通常有一种主要的方法来完成某项工作,而在R中,有许多支持不同的做事方法的程序包(例如,至少有六个程序包可以制作成对图)。
聚集玩家
探索此类数据的一种好方法是生成聚类图。这些将显示哪些球员最相似。
[R

Python

为了正确集群,我们删除任何非数字列或列缺少值(NA,Nan,等)。在R中,我们通过在每列上应用一个函数来完成此操作,如果该函数缺少任何值或不是数字,则将其删除。然后,我们使用集群程序包执行k均值并5在我们的数据中找到集群。我们设置一个随机种子set.seed用于能够再现我们的结果。
在Python中,我们使用主要的Python机器学习包scikit-learn来拟合k-均值聚类模型并获得我们的聚类标签。我们使用非常相似的方法来准备我们在R中使用的数据,只是我们使用get_numeric_data和dropna方法来删除非数字列和缺少值的列。
按集群绘制玩家
现在,我们可以按组绘制玩家以发现模式。一种方法是首先使用PCA使数据二维化,然后绘制数据,并根据聚类关联对每个点进行着色。
[R

Python

绘制了我们的数据散点图,并根据聚类对数据的图标进行了阴影处理或更改。在R中,使用的clusplot功能是群集库的一部分。我们通过pccompR中内置的功能执行了PCA 。
使用Python,我们在scikit-learn库中使用了PCA类。我们使用matplotlib来创建绘图。
分为训练和测试集
如果我们想进行监督式机器学习,将数据分为训练集和测试集是个好主意,这样就不会过拟合。
[R

Python

Python中对R进行比较,我们可以看到,R有更多的数据分析侧重建宏,喜欢floor,sample和set.seed,而这些是通过包称为在Python( ,math.floor,)。random.sample random.seed在Python中,最新版本的pandas带有一种sample方法,该方法返回从源数据帧中随机采样的一定比例的行-这使代码更加简洁。在R中,有一些程序包使采样更简单,但没有比使用内置sample函数简单得多。在这两种情况下,我们都设置一个随机种子以使结果可重复。
单变量线性回归
假设我们要根据每个球员的射门得分来预测每个球员的助攻数。
[R

Python

Scikit-learn具有线性回归模型,我们可以拟合并从中生成预测。[R依赖于内置lm和predict功能。predict根据传入的拟合模型的类型,其行为将有所不同-它可以与各种拟合模型一起使用。
计算模型的摘要统计信息
[R

Python

如果要获取有关拟合的摘要统计信息(如r平方值),则在Python中要比在R中做更多的事情。使用R,我们可以使用内置summary函数来获取有关模型的信息。对于Python,我们需要使用statsmodels包,该包允许在Python中使用许多统计方法。我们得到相似的结果,尽管通常在Python中进行统计分析会比较困难,并且R中存在的某些统计方法在Python中不存在。
拟合随机森林模型
我们的线性回归在单变量情况下效果很好,但是我们怀疑数据中可能存在非线性。因此,我们想拟合一个随机森林模型。
[R

Python

这里的主要区别是我们需要使用R中的randomForest库来使用该算法,而它是内置于scikit-learn中的Python。scikit-learn具有一个统一的接口,可与Python中的许多不同的机器学习算法一起使用,并且Python中每种算法通常只有一个主要实现。使用R,有许多较小的程序包,其中包含各个算法,通常使用不一致的方法来访问它们。这导致算法的多样性更大(很多都有几种实现方式,许多是刚从研究实验室中脱颖而出的),但是却对可用性造成了影响。
计算误差
现在我们已经拟合了两个模型,让我们计算误差。我们将使用MSE。
[R

Python

在Python中,scikit-learn库具有我们可以使用的各种错误度量。在R中,可能会有一些较小的库来计算MSE,但是手动使用两种语言都非常容易。几乎可以肯定,由于参数调整而导致的错误之间存在很小的差异,这并不重要。
下载网页
现在我们掌握了2013-2014年NBA球员的数据,下面我们来补充一些数据。我们只看到一个框得分从NBA总决赛在这里,以节省时间。
[R

Python

在Python中,请求包使所有网站都可以使用一致的API轻松下载网页。在R中,RCurl提供了类似的简单请求方法。两者都将网页下载为字符数据类型。注意:此步骤对于R中的下一步骤是不必要的,但出于比较目的而显示。
提取玩家框得分
现在我们有了网页,我们需要对其进行解析以提取玩家的分数。
[R
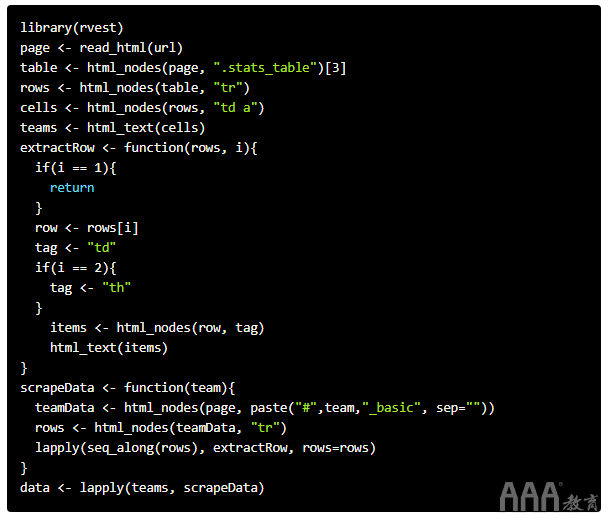
Python

这将创建一个包含两个列表的列表,第一个列表的框得分为CLE,第二个列表框得分为GSW。两者都包含标题,以及每个玩家及其游戏中的统计信息。我们现在不会将其转换为更多的训练数据,但是可以轻松地将其转换为可以添加到我们的nba数据框中的格式。
R代码比Python代码更复杂,因为没有使用正则表达式选择项目的便捷方法,因此我们必须进行其他解析才能从HTML中获取团队名称。R还不鼓励使用for循环,而是希望沿向量应用函数。我们lapply经常这样做,但是由于我们需要根据是否是标题而对每一行进行不同的处理,因此我们将所需项的索引以及整个rows列表传递给函数。
我们使用rvest广泛使用的R Web抓包来提取所需的数据。请注意,我们可以将url直接传递到rvest中,因此R中不需要最后一步。
在Python中,我们使用BeautifulSoup,这是最常用的Web抓包。它使我们能够遍历标签并以简单的方式构造列表列表。
结论中的Python vs R
我们已经看过如何使用R和Python分析数据集。我们没有涉及许多任务,例如,保留分析结果,与他人共享结果,进行测试并使产品准备就绪并进行更多可视化。关于此主题还有很多要讨论的内容,但是基于上面所做的事情,我们可以得出一些有意义的结论:
R的功能更多,Python的更面向对象。
正如我们从,和其他函数中看到的那样lm,predictR让函数完成了大部分工作。将此与LinearRegressionPython中的类以及sample数据框上的方法进行对比。
R具有更多内置的数据分析功能,Python依赖于软件包。
在查看摘要统计信息时,我们可以使用summaryR中的内置函数,但必须statsmodels在Python中导入该包。数据框是R中的内置构造,但必须通过pandasPython中的包导入。
Python具有用于数据分析任务的“主要”软件包,R具有较大的小型软件包生态系统。
使用Python,我们可以使用scikit-learn软件包进行线性回归,随机森林等等。它提供一致的API,并且维护良好。在R中,我们有更多的软件包多样性,但也有更大的碎片化和更少的一致性(线性回归是内置的lm,randomForest是单独的软件包,等等)。
R通常具有更多的统计支持。
R被构建为一种统计语言,它可以显示。statsmodelsPython和其他软件包中的XML提供了不错的统计方法覆盖范围,但是R生态系统要大得多。
在Python中执行非统计性任务通常更为直接。
使用BeautifulSoup和请求等维护良好的库,Python中的Web抓取要比R中的要容易得多。这适用于我们没有仔细研究的其他任务,例如保存到数据库,部署Web服务器或运行复杂的工作流程。
两者中的数据分析工作流之间有很多相似之处。
R和Python之间都有明显的灵感点(pandas数据框受R数据框启发,rvest软件包受BeautifulSoup启发),并且两个生态系统都在不断壮大。令人惊讶的是,两种语言中许多常见任务的语法和方法多么相似。
Python vs R的最终结论
在AAA教育,我们以Python课程而闻名,但是我们完全按照R路径重新设计和发布了Data Analyst,因为我们认为R是数据科学的另一种至关重要的语言。我们认为两种语言是互补的,每种语言都有其优点和缺点。正如本演练所证明的,任何一种语言都可以用作您唯一的数据分析工具。两种语言在语法和方法上都有很多相似之处,并且您都不会错。
最终,您可能最终想要学习Python 和 R,以便可以利用两种语言的优势,根据需要在每个项目中选择一种或另一种。当然,如果您要在数据科学领域中寻找一席之地,那么同时了解两者也会使您成为更灵活的求职者。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






